- Bioinformatics
applies the tools of computation and analysis to the capture and interpretation of biological data. Utilizing expertise from computer science, mathematics, physics, and biology, bioinformatics rigorously quantitates biological phenomena, from population dynamics to protein function.
- Cannabinoids
are several structural classes of compounds found primarily in the cannabis plant. Most animals, with the exception of insects, possess cannabinoid receptors that are stimulated by cannabinoids. The most well-known cannabinoid is (delta-9) tetrahydrocannabinol (THC), the primary intoxicating compound in cannabis. Cannabidiol (CBD) is a major constituent of temperate Cannabis plants and a minor constituent in tropical varieties. At least 113 distinct phytocannabinoids have been isolated from cannabis. Phytocannabinoids can be found in other plants as well, such as rhododendron, licorice, liverwort, and even Echinacea.
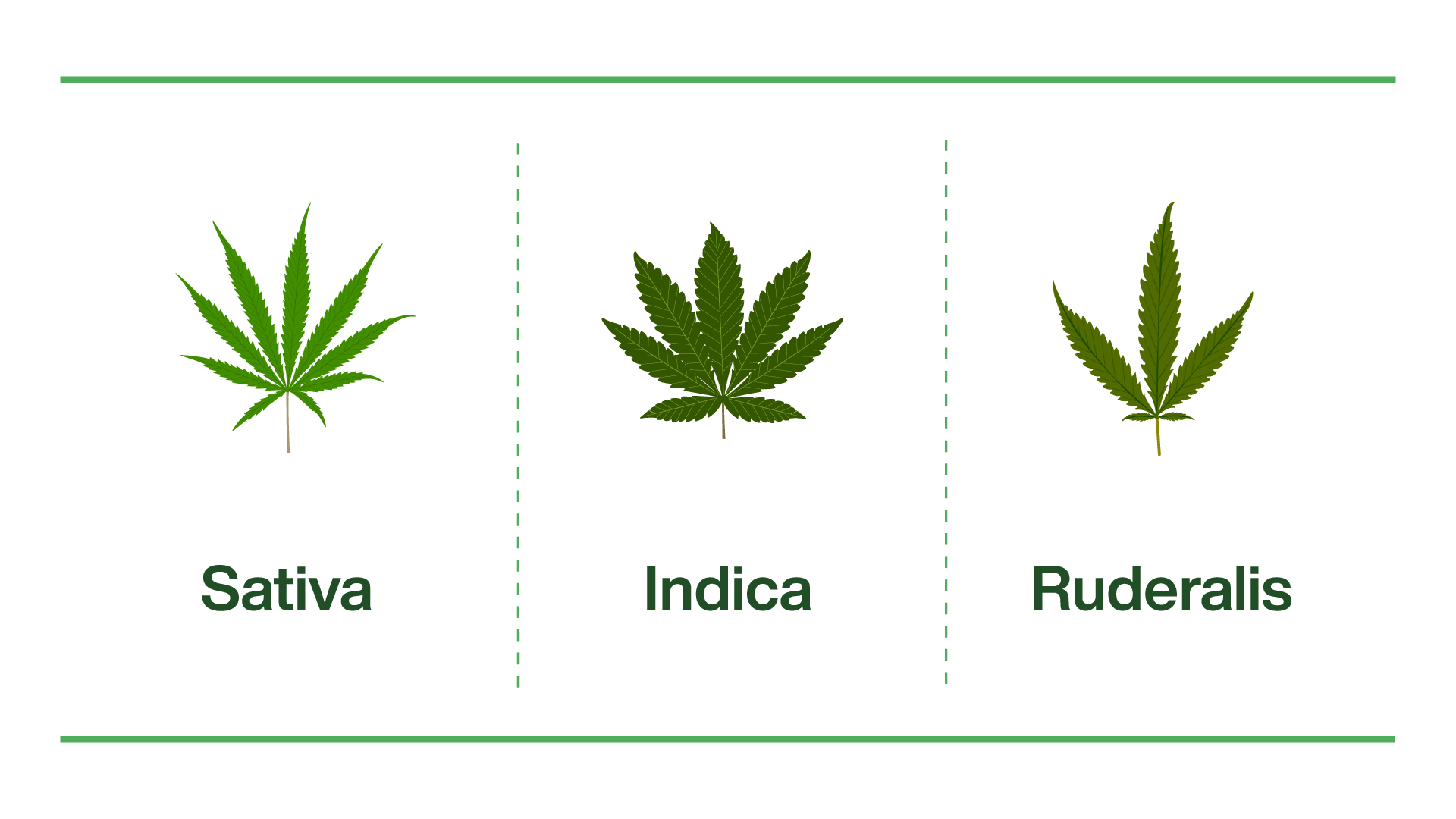
- Cannabis sativa
was domesticated in Central Asia over 5000 years ago. Cannabis varieties with low levels of psychoactive cannabinoids are used for the production of fiber and oilseed. However, the terpene- and cannabinoid-rich resin (with its various psychoactive and medicinal properties) is the most valuable cannabis product today. The resin is produced and accumulates in glandular trichomes that densely cover the surfaces of female (pistillate) inflorescences and, to a lesser degree, the foliage of the plants. In total, more than 150 different terpenes and approximately 100 different cannabinoids have been identified in various cannabis resins. The predominant cannabinoids in cannabis grown for medicinal or recreational use are Δ9-tetrahydrocannabinolic acid (THCA) and cannabidiolic acid (CBDA). Volatile terpenes (monoterpenes and sesquiterpenes) bestow the fragrance variations that influence consumer preference.
Despite being the foundation of a multi-billion dollar global industry, scientific knowledge and research on cannabis is far behind that of other high-value crops. For a long time, legal restrictions prevented many researchers from studying cannabis, its products, and its therapeutic properties. Cannabis resin contains hundreds of different terpene and cannabinoid metabolites. Many of these metabolites have not been conclusively identified. The genomic and biosynthetic systems of these metabolites in cannabis and the factors that affect their variability remain largely uninvestigated.
- Cannabis indica
is a cannabis species that produces large amounts of tetrahydrocannabinol (THC) and is used to make hashish in India. The high concentrations of THC provide euphoric effects, making it popular for recreational, alternative medicine, and clinical research applications.
- Cannabis ruderalis
Its native range extends from Central Europe to Russia. It contains a relatively low amount of tetrahydrocannabinol (THC). Some scholars accept C. ruderalis as its own species because its unique traits and phenotypes distinguish it from C. indica and C. sativa. Others debate whether C. ruderalis is merely a subspecies of C. sativa. As of 2022, the consensus among plant taxonomic databases designates it as Cannabis sativa var. ruderalis.
- DNA
(or deoxyribonucleic acid) is a long molecule that contains the unique genetic code of all living things. Like a recipe book, it holds the instructions for making all the proteins in our bodies. The DNA code contains the genetic information needed to make the proteins and molecules essential for our growth, development and health. DNA molecules allow this information to be passed from one generation to the next.
- DNA sequencing
is a laboratory process used to determine the exact sequence (order) of the four building blocks, or bases, that make up regions of DNA. Information is stored in DNA as a code, made by arranging the four bases (identified by the letters A, C, G, and T) in different, specific orders.
- Genetics
is the study of genes and heredity. Heredity is the passing of genetic information and traits (such as eye color and an increased chance of getting a certain disease) from parents to offspring.
- Genetic Code
is the set of rules used by living cells to express information encoded within genetic material (DNA or the messenger ribonucleic acid (mRNA) sequences transcribed from it). This mRNA molecule uses a series of triplet codes (codons) to instruct ribosomes to synthesize protein in a process, known as translation. The mRNA nucleotides are abbreviated with the letters A, U, G and C (mRNA uses U, while DNA uses T). The genetic code is basically the same for all organisms and is easily described by a simple table with 64 codon entries.
- Genetic engineering
is the process of manipulating genes in plants (and other organisms) to produce desired traits.
- Genome or Gene editing
is the rational alteration of the genetic material in a living organism by inserting, replacing, or deleting a DNA sequence, typically with the aim of improving some characteristic or correcting a genetic defect.
- Metabolomics
describes the chemical processes involving metabolites, the small molecule substrates, intermediates, and products of cell metabolism. The metabolome represents the complete set of metabolites in a biological cell, tissue, organ, or organism.
- Molecular breeding
(MAS) is a technique where DNA markers that are tightly linked to visible (phenotypic) traits are used to select for a particular breeding objective.
- Molecular genetics
is the study of the molecular structure of DNA, its cellular activities (including its replication), and its influence in determining the structure and functions of an organism.